实现 Redis 集群
本文进度对应的代码仓库:Redis 集群
在前面章节中,我们实现了单机版的 Redis。接下来,我们将实现 Redis 集群。Redis 集群是一个分布式的 Redis 实现,它允许将数据分布在多个节点上,从而提高性能和可用性。
我们为什么需要 Redis 集群?因为单机版的 Redis 有一些限制,比如:
- 单机版的 Redis 只能使用单个节点,无法利用多核 CPU 的性能。
- 单机版的 Redis 的可用性依赖于单个节点,如果节点宕机,数据将丢失。
- 单机版的 Redis 的性能受限于单个节点的性能,无法使用多个节点的性能。
- 单机版的 Redis 的扩展性有限,无法轻易增加更多的节点以提升性能。
Redis 集群的运作原理
Redis 集群是一个分布式的 Redis 实现,它允许将数据分布在多个节点上。
例如有四个节点 A、B、C、D,Redis 集群会将数据分布在这四个节点上。每个节点负责一部分数据。
当发生写入操作时,Redis 集群会将数据写入到对应的节点上。当发生读取操作时,Redis 集群会从对应的节点上读取数据。
那么 Redis 集群是如何将数据分布在多个节点上的呢?这就需要用到一致性哈希算法。
集群实现算法
传统哈希算法
传统的哈希算法是将数据映射到一个固定大小的哈希表中。假设我们有一个大小为 N 的哈希表,我们可以使用哈希函数将数据映射到哈希表中的一个位置。
例如我们有四个节点 A、B、C、D。
有一个新的键 K1,我们使用哈希函数计算出 K1 的哈希值为 X,然后对节点数 4 取模,得到 X % 4 = 2。我们将 K1 存储在节点 C 中。
取数据的时候,我们同样使用哈希函数计算出 K1 的哈希值为 X,然后对节点数 4 取模,得到 X % 4 = 2。我们从节点 C 中读取 K1 的值。
这就是传统的哈希算法来实现的集群。
但是这样会存在一个问题:当我们增加一个节点 E 时,所有的键都需要重新计算哈希值并重新分配到新的节点上。这会导致大量的数据迁移,影响性能。
一致性哈希算法
一致性哈希算法是为了解决传统哈希算法的问题而提出的。它的核心思想是将节点和数据都映射到一个虚拟的环上。
在这个环上,节点和数据都是一个个的点。我们可以使用哈希函数将节点和数据映射到这个环上。
例如我们有四个节点 A、B、C、D。我们可以将它们映射到一个虚拟的环上:
A
/ \
D B
\ /
C我们可以给每个节点分配一个哈希值,可以使用节点名字、IP 地址等来计算。假设 A、B、C、D 的位置分别为 10056、24567、49837、56789。
有一个新的键 K1,我们使用哈希函数计算出 K1 的哈希值为 12345。我们在环上顺时针查找,我们发现离 K1 最近的节点是 B。我们将 K1 存储在节点 B 中。
那么增加一个节点 E 时,我们只需要将 E 映射到环上,例如 E 的地址是 34567。那么我们需要把 E 插入到 B 和 C 之间。之前存放在 C 中的数据会有一部分变得离 E 更近,我们需要将这些数据迁移到 E 中。但是其他节点不受影响,这样就避免了大量的数据迁移。
这就是一致性哈希算法的基本原理。
实现集群
定义 Node Map
在 lib 下新建一个 consistent_hash 文件夹,在下面新建 consistent_hash.go 文件,定义一个 NodeMap 结构体,用来存储节点的信息。
在结构体中,我们需要定义下面的组件:
hashFunc:哈希函数,用来计算节点的哈希值。输出是一个 uint32 类型的值,这是因为在 Redis 中,哈希值是一个 32 位的整数。nodeHashs:节点的哈希值列表,用来存储所有节点的哈希值。我们需要将节点的哈希值存储在一个切片中,以便后续查找。这个切片的内容后续是要排序的(Go 的排序方法支持 int 类型)所以我们使用 int 来存储。在 64 位的机器中,int 的正数部分长度为 32 位,和上面的 uint32 一致,所以可以兼容。nodehashMap:节点的哈希值和节点名称的映射关系,用来存储节点的名称和哈希值之间的关系。便于通过哈希值查找节点。
package consistenthash
type NodeMap struct {
hashFunc func(data []byte) uint32
nodeHashs []int
nodehashMap map[int]string
}然后创建一个 NewNodeMap 函数,用来初始化 NodeMap 结构体。
func NewNodeMap(hashFunc func(data []byte) uint32) *NodeMap {
m := &NodeMap{
hashFunc: hashFunc,
nodehashMap: make(map[int]string),
}
if m.hashFunc == nil {
m.hashFunc = crc32.ChecksumIEEE
}
return m
}在这里初始化 hashFunc,如果没有传入,则使用默认的 CRC32 哈希函数。
不用初始化 nodeHashs,因为我们后续会在添加节点时初始化。
接下来创建一个 IsEmpty 函数,用来判断 NodeMap 是否为空。
func (m *NodeMap) IsEmpty() bool {
return len(m.nodehashMap) == 0
}实现一致性哈希算法
在包中创建一个 AddNodes 函数,用来添加节点。
传入的参数是一个字符串切片,表示节点的名称。我们需要遍历这个切片,将每个节点的名称转换成哈希值,并存储在 nodeHashs 列表中。同时,我们还需要将节点的名称和哈希值之间的映射关系存储在 nodehashMap 中。
完成后,nodeHashs 列表中存储的就是所有节点的哈希值。我们需要对这个列表进行排序,这里使用 Go 的内置排序方法。sort.Ints 底层使用的是快速排序算法,时间复杂度为 O(nlogn),空间复杂度为 O(logn)。
func (m *NodeMap) AddNodes(nodes ...string) {
for _, node := range nodes {
if node == "" {
continue
}
hash := int(m.hashFunc([]byte(node)))
m.nodeHashs = append(m.nodeHashs, hash)
m.nodehashMap[hash] = node
}
sort.Ints(m.nodeHashs)
}接下来创建一个 PickNode 函数,用来根据给定的键值选择一个节点。
在这里我们使用 sort.Search 方法来查找离给定键值最近的节点。
sort.Search(n, f func(i int) bool) int这个函数会在 [0, n) 的区间上进行二分查找,返回最小的满足 f(i) == true 的下标 i。如果所有的 f(i) 都是 false,那就返回 n。
// PickNode picks a node based on the key, returning the node that is closest to the hash of the key
func (m *NodeMap) PickNode(key string) string {
if m.IsEmpty() {
return ""
}
hash := int(m.hashFunc([]byte(key)))
index := sort.Search(len(m.nodeHashs), func(i int) bool {
return m.nodeHashs[i] >= hash
})
// If the hash is greater than all node hashes, Int.Search returns len(m.nodeHashs)
// So we need to wrap around to the first node
if index == len(m.nodeHashs) {
index = 0
}
return m.nodehashMap[m.nodeHashs[index]]
}在这里,如果 index 等于 len(m.nodeHashs),说明给定的键值大于所有节点的哈希值,我们需要将其设置为 0,表示从第一个节点开始。
Cluster Database 和客户端
在之前章节中,我们在 database/database.go 中实现了一个 Database 结构体,用来存储数据。这是一个单机版的数据库实现。
后面我们要给每个实例创建一个 Cluster Database 用于转发请求到单机版的数据库中。如下图所示,每个实例都有一个 Cluster Database 和一个 Standalone Database,Cluster Database 不负责具体的业务,而是将请求转发到 Standalone Database 中。
------------------------------
| cluster_database |
|----------------------------|
| standalone_database |
------------------------------我们到 database/database.go 中,对原来的 Database 进行重命名,更名为 StandaloneDatabase。可以使用 VSCode 的重命名功能。
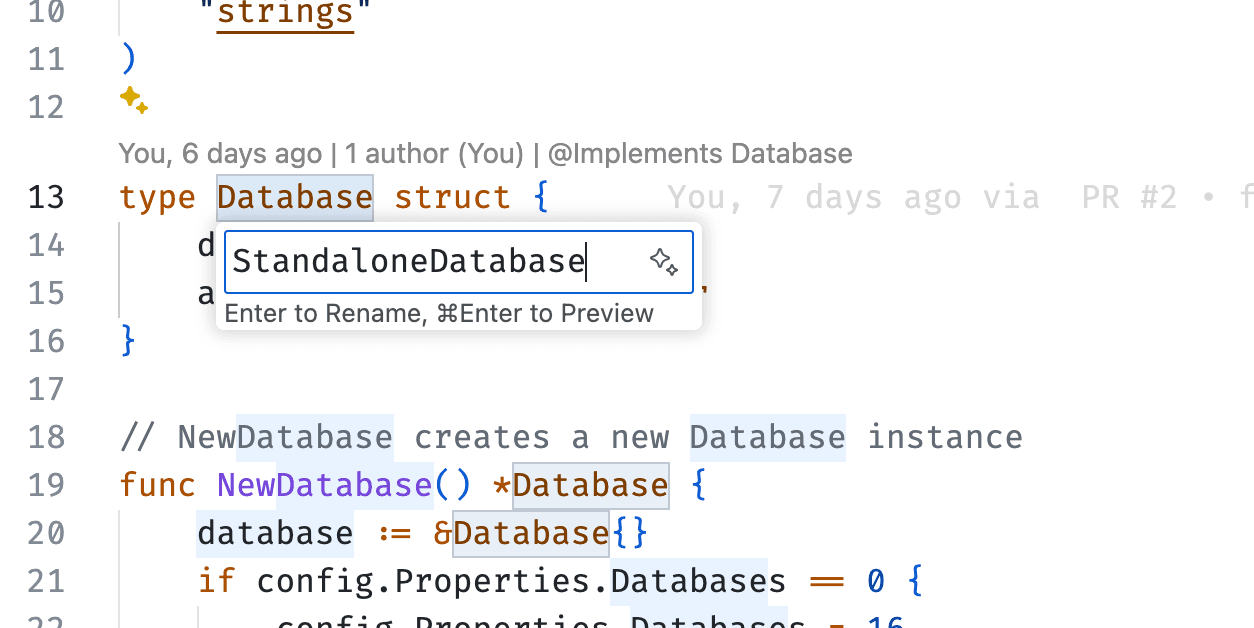
然后把 NewDatabase 函数重命名为 NewStandaloneDatabase。
得到下面的代码:
package database
import (
"redigo/aof"
"redigo/config"
"redigo/interface/resp"
"redigo/lib/logger"
"redigo/resp/reply"
"strconv"
"strings"
)
type StandaloneDatabase struct {
dbSet []*DB
aofHandler *aof.AofHandler
}
// NewStandaloneDatabase creates a new StandaloneDatabase instance
func NewStandaloneDatabase() *StandaloneDatabase {
database := &StandaloneDatabase{}
if config.Properties.Databases == 0 {
config.Properties.Databases = 16
}
database.dbSet = make([]*DB, config.Properties.Databases)
for i := range database.dbSet {
db := MakeDB()
db.index = i
database.dbSet[i] = db
}
if config.Properties.AppendOnly {
aofHandler, err := aof.NewAofHandler(database)
if err != nil {
panic(err)
}
database.aofHandler = aofHandler
for _, db := range database.dbSet {
// create new variable to avoid closure capturing the loop variable
sdb := db
sdb.addAof = func(line CmdLine) {
database.aofHandler.AddAof(sdb.index, line)
}
}
}
return database
}
// Exec executes a command on the database
func (d *StandaloneDatabase) Exec(client resp.Connection, args [][]byte) resp.Reply {
defer func() {
if err := recover(); err != nil {
logger.Error("Database Exec panic:" + err.(error).Error())
}
}()
cmdName := strings.ToLower(string(args[0]))
if cmdName == "select" {
if len(args) != 2 {
return reply.MakeArgNumErrReply("select")
}
return execSelect(client, d, args[1:])
}
// Get the current database index from the client connection
db := d.dbSet[client.GetDBIndex()]
return db.Exec(client, args)
}
func (d *StandaloneDatabase) AfterClientClose(c resp.Connection) {
}
func (d *StandaloneDatabase) Close() {
}
// execSelect sets the current database for the client connection.
// select x
func execSelect(c resp.Connection, database *StandaloneDatabase, args [][]byte) resp.Reply {
dbIndex, err := strconv.Atoi(string(args[0]))
if err != nil {
return reply.MakeStandardErrorReply("ERR invalid DB index")
}
if dbIndex < 0 || dbIndex >= len(database.dbSet) {
return reply.MakeStandardErrorReply("ERR DB index out of range")
}
c.SelectDB(dbIndex)
return reply.MakeOKReply()
}注意,在 resp/handler/handler.go 中,我们需要将 NewDatabase 函数使用 NewStandaloneDatabase 函数替换掉。
func MakeHandler() *RespHandler {
// 修改这里
db := database.NewStandaloneDatabase()
return &RespHandler{
db: db,
}
}然后把 database/database.go 文件名改为 standalone_database.go。
接下来在根目录建立 cluster 文件夹。
假如我们有节点迁移的需要,例如,A 要迁移数据给 B,那么他们之间如何进行通信呢?我们可以让 A 节点成为 B 节点的客户端,B 节点成为 A 节点的服务端。这样就可以通过网络进行通信了。
那么,接下来我们要实现这个客户端,供后续的节点之间进行通信。
我们这里实现的 Redis 客户端,就是让一个节点可以像普通客户端那样“操作”其他节点。它不仅仅是用来做集群内部转发,其实直接拿来写小工具、做测试,也都能用。
在 resp 包下新建一个 client 文件夹,在下面新建 client.go 文件,定义一个 Client 结构体,用来存储客户端的信息。
首先,我们先看下客户端结构体的定义:
type Client struct {
conn net.Conn
pendingReqs chan *request // wait to send
waitingReqs chan *request // waiting response
ticker *time.Ticker
addr string
working *sync.WaitGroup // its counter presents unfinished requests(pending and waiting)
}Client 结构体内部维护了一个底层的 TCP 连接(conn),两个 channel 分别负责“待发送的请求”和“已发送待响应的请求”。这里用到的 channel 带缓冲,可以减少并发场景下的阻塞。还有一个定时器 ticker,用来做定时心跳。working 这个 WaitGroup 则用来优雅关闭客户端——只有所有请求都处理完,连接才会真正关闭。
接着是每条请求的结构:
type request struct {
id uint64
args [][]byte
reply resp.Reply
heartbeat bool
waiting *wait.Wait
err error
}每个 request 记录了命令参数、请求结果、错误信息、是否是心跳、以及一个等待工具(用于阻塞等待响应)。
初始化客户端时,会建立 TCP 连接,并初始化两个请求队列:
func MakeClient(addr string) (*Client, error) {
conn, err := net.Dial("tcp", addr)
if err != nil {
return nil, err
}
return &Client{
addr: addr,
conn: conn,
pendingReqs: make(chan *request, 256),
waitingReqs: make(chan *request, 256),
working: &sync.WaitGroup{},
}, nil
}通过 net.Dial 连接到指定地址,两个带缓冲的 channel 也分别创建出来。连接不上的话直接报错返回。
net.Dial 是 net 包提供的一个函数,用于创建一个 TCP 连接。它会阻塞直到连接成功或失败。
客户端一旦创建完毕,调用 Start 方法就会开启整个异步的流程:
func (client *Client) Start() {
client.ticker = time.NewTicker(10 * time.Second)
go client.handleWrite()
go func() {
err := client.handleRead()
if err != nil {
logger.Error(err)
}
}()
go client.heartbeat()
}Start 会启动三个 goroutine。第一个负责写(发请求),第二个负责读(收响应),第三个就是心跳,定时 ping。这里全部是异步,互不干扰。这样不管请求阻塞还是服务器响应慢,都不会让客户端卡死。
那怎么发送请求呢?很简单,只要调用 Send 就行:
// Send sends a request to redis server
func (client *Client) Send(args [][]byte) resp.Reply {
request := &request{
args: args,
heartbeat: false,
waiting: &wait.Wait{},
}
request.waiting.Add(1)
client.working.Add(1)
defer client.working.Done()
client.pendingReqs <- request
timeout := request.waiting.WaitWithTimeout(maxWait)
if timeout {
return reply.MakeStandardErrorReply("server time out")
}
if request.err != nil {
return reply.MakeStandardErrorReply("request failed")
}
return request.reply
}每次 Send,都把请求包装成 request,放进 pendingReqs 发送队列里。外部会阻塞等待,最多等 3 秒,如果超时就直接报错返回。等响应来了(或出错),就能继续执行。
负责真正“写”请求的是 handleWrite 这个循环:
func (client *Client) handleWrite() {
for req := range client.pendingReqs {
client.doRequest(req)
}
}只要 pendingReqs 有新请求,就调用 doRequest 写入 TCP 连接。请求序列化用之前实现的 RESP 协议。
func (client *Client) doRequest(req *request) {
if req == nil || len(req.args) == 0 {
return
}
re := reply.MakeMultiBulkReply(req.args)
bytes := re.ToBytes()
_, err := client.conn.Write(bytes)
i := 0
for err != nil && i < 3 {
err = client.handleConnectionError(err)
if err == nil {
_, err = client.conn.Write(bytes)
}
i++
}
if err == nil {
client.waitingReqs <- req
} else {
req.err = err
req.waiting.Done()
}
}这一步先把命令编码成字节流,写进连接。如果写失败,会尝试重连(最多 3 次),重连成功后继续发。如果最终写还是失败,就直接把错误反馈回去。写成功的话,把请求放进 waitingReqs,等待响应。
读响应这一块是异步的:
func (client *Client) handleRead() error {
ch := parser.ParseStream(client.conn)
for payload := range ch {
if payload.Err != nil {
client.finishRequest(reply.MakeStandardErrorReply(payload.Err.Error()))
continue
}
client.finishRequest(payload.Data)
}
return nil
}它使用 RESP 解析器不断解析 Redis 的响应流。每解析出一条结果,就交给 finishRequest:
func (client *Client) finishRequest(reply resp.Reply) {
defer func() {
if err := recover(); err != nil {
debug.PrintStack()
logger.Error(err)
}
}()
request := <-client.waitingReqs
if request == nil {
return
}
request.reply = reply
if request.waiting != nil {
request.waiting.Done()
}
}这里通过 waitingReqs 拿到原始请求,把响应结果绑定上,并唤醒外部等待 Send 的那一方。这样请求和响应一一配对,不会乱序。
心跳机制也是自动跑的:
func (client *Client) heartbeat() {
for range client.ticker.C {
client.doHeartbeat()
}
}
func (client *Client) doHeartbeat() {
request := &request{
args: [][]byte{[]byte("PING")},
heartbeat: true,
waiting: &wait.Wait{},
}
request.waiting.Add(1)
client.working.Add(1)
defer client.working.Done()
client.pendingReqs <- request
request.waiting.WaitWithTimeout(3 * time.Second)
}每隔 10 秒就发一个 PING,判断连接是否可用,如果发现断开了,会自动重连。
重连的逻辑也进行封装:
func (client *Client) handleConnectionError(err error) error {
err1 := client.conn.Close()
if err1 != nil {
if opErr, ok := err1.(*net.OpError); ok {
if opErr.Err.Error() != "use of closed network connection" {
return err1
}
} else {
return err1
}
}
conn, err1 := net.Dial("tcp", client.addr)
if err1 != nil {
logger.Error(err1)
return err1
}
client.conn = conn
go func() {
_ = client.handleRead()
}()
return nil
}如果遇到连接异常,就先关掉老连接,然后重新建立连接。重连成功后会重启读响应的 goroutine,确保不会丢请求。
最后,关闭客户端时要优雅退出:
func (client *Client) Close() {
client.ticker.Stop()
close(client.pendingReqs)
client.working.Wait()
_ = client.conn.Close()
close(client.waitingReqs)
}先停心跳,关闭发送队列,等待所有请求处理完,再关闭底层连接和队列。这能确保没有请求被遗漏或丢失。
整个客户端实现下来,其实思路就是“异步写请求 + 异步收响应 + 定时心跳 + 自动重连 + 优雅关闭”。它是集群节点之间通信的桥梁,也是我们搭建分布式 Redis 系统的关键基础。
它本质就是一个 TCP 客户端。
这个客户端的使用方式非常简单:只需通过 MakeClient 创建连接并调用 Start 启动它,然后就可以像操作普通 Redis 一样使用 Send 方法发送命令。每个命令通过字节数组形式传入,内部会自动序列化、发送并等待响应。使用完毕后,调用 Close 即可优雅地关闭连接。
继续往后,我们会借助这个客户端,每个节点可以像“普通用户”一样去操作其它节点的数据,实现跨节点的请求路由、转发和同步。集群的雏形就这样搭起来了。
好的,我们来继续。
在 cluster 文件夹下新建 cluster_database.go 文件,定义一个 ClusterDatabase 结构体,用来存储集群的信息。
这个结构体需要实现我们之前定义好的 interface/database.go 中的 Database 接口。我们需要实现 Exec 和 AfterClientClose 、Close 方法。
type Database interface {
Exec(client resp.Connection, args [][]byte) resp.Reply
AfterClientClose(c resp.Connection)
Close()
}现在先写出这个结构体的大纲:
type ClusterDatabase struct {
}
// MakeClusterDatabase creates a new ClusterDatabase instance
func MakeClusterDatabase() *ClusterDatabase {
return &ClusterDatabase{}
}
// Exec executes a command on the cluster database
func (c *ClusterDatabase) Exec(client resp.Connection, args [][]byte) resp.Reply {
return nil
}
// Close closes the cluster database
func (c *ClusterDatabase) Close() {
}
// AfterClientClose is called after a client closes
func (c *ClusterDatabase) AfterClientClose(client resp.Connection) {
}然后这里要引入连接池概念。想象一下,如果每次节点 A 需要向节点 B 发送命令时(比如转发一个 SET 请求),都要重新建立一次 TCP 连接,那开销就太大了。建立连接本身有延迟,而且会消耗不少系统资源。频繁地创建和销毁连接,对性能是很大的拖累。
连接池就是用来解决这个问题的。它会预先为每个目标节点(集群中的其他伙伴)创建并维护一组连接。当需要和某个节点通信时,我们就从池子里“借”一个现成的连接,用完再“还”回去,而不是每次都新建。这样大大提高了效率。我们之前实现的那个 client 客户端,正好可以作为连接池里管理的基础连接对象。连接池的作用就是管理这些到其他节点的客户端实例。
这里我们实现引入一个开源的连接池库 go-commons-pool,它是一个高性能的连接池实现,支持多种类型的连接池,包括对象池、连接池等。我们可以使用它来管理到其他节点的连接。
go get github.com/jolestar/go-commons-pool/v2接下来我们补全 ClusterDatabase 结构体,它需要包含以下几个字段:
self:当前节点的 ID。nodes:集群中所有节点的 ID 列表。peerPicker:一致性哈希算法的实现,用来选择节点。peerconn:连接池,用来管理到其他节点的连接。db:当前节点的数据库实例。
type ClusterDatabase struct {
self string // self node id
nodes []string // cluster nodes
peerPicker *consistenthash.NodeMap // consistent hash ring
peerConn map[string]*pool.ObjectPool // connection pool for each node
db database.Database // database instance
}接下来我们为 peerConn 创建一些基础的设施,在 cluster 包下创建一个 cluster_pool.go 文件。
我们点击进入 pool.ObjectPool ,来观察一下如何使用这个连接池。
// ObjectPool is a generic object pool
type ObjectPool struct {
AbandonedConfig *AbandonedConfig
Config *ObjectPoolConfig
closed bool
closeLock sync.Mutex
evictionLock sync.Mutex
idleObjects *collections.LinkedBlockingDeque
allObjects *collections.SyncIdentityMap
factory PooledObjectFactory
createCount concurrent.AtomicInteger
destroyedByEvictorCount concurrent.AtomicInteger
destroyedCount concurrent.AtomicInteger
destroyedByBorrowValidationCount concurrent.AtomicInteger
evictor *time.Ticker
evictorStopChan chan struct{}
evictorStopWG sync.WaitGroup
evictionIterator collections.Iterator
}
// NewObjectPool return new ObjectPool, init with PooledObjectFactory and ObjectPoolConfig
func NewObjectPool(ctx context.Context, factory PooledObjectFactory, config *ObjectPoolConfig) *ObjectPool {
return NewObjectPoolWithAbandonedConfig(ctx, factory, config, nil)
}
// NewObjectPoolWithDefaultConfig return new ObjectPool init with PooledObjectFactory and default config
func NewObjectPoolWithDefaultConfig(ctx context.Context, factory PooledObjectFactory) *ObjectPool {
return NewObjectPool(ctx, factory, NewDefaultPoolConfig())
}
// NewObjectPoolWithAbandonedConfig return new ObjectPool init with PooledObjectFactory, ObjectPoolConfig, and AbandonedConfig
func NewObjectPoolWithAbandonedConfig(ctx context.Context, factory PooledObjectFactory, config *ObjectPoolConfig, abandonedConfig *AbandonedConfig) *ObjectPool {
pool := ObjectPool{factory: factory, Config: config,
idleObjects: collections.NewDeque(math.MaxInt32),
allObjects: collections.NewSyncMap(),
createCount: concurrent.AtomicInteger(0),
destroyedByEvictorCount: concurrent.AtomicInteger(0),
destroyedCount: concurrent.AtomicInteger(0),
AbandonedConfig: abandonedConfig}
pool.StartEvictor()
return &pool
}我们可以看到这里有多个初始化函数,最简单的就是 NewObjectPoolWithDefaultConfig,它会使用默认的配置来创建连接池。
我们就使用这个函数来创建连接池。
这个方法要我们传入一个 PooledObjectFactory,它是一个接口,用来创建连接池中的对象。我们需要实现这个接口,来创建连接池中的对象。
这个接口的定义如下:
type PooledObjectFactory interface {
/**
* Create a pointer to an instance that can be served by the
* pool and wrap it in a PooledObject to be managed by the pool.
*
* return error if there is a problem creating a new instance,
* this will be propagated to the code requesting an object.
*/
MakeObject(ctx context.Context) (*PooledObject, error)
/**
* Destroys an instance no longer needed by the pool.
*/
DestroyObject(ctx context.Context, object *PooledObject) error
/**
* Ensures that the instance is safe to be returned by the pool.
*
* return false if object is not valid and should
* be dropped from the pool, true otherwise.
*/
ValidateObject(ctx context.Context, object *PooledObject) bool
/**
* Reinitialize an instance to be returned by the pool.
*
* return error if there is a problem activating object,
* this error may be swallowed by the pool.
*/
ActivateObject(ctx context.Context, object *PooledObject) error
/**
* Uninitialize an instance to be returned to the idle object pool.
*
* return error if there is a problem passivating obj,
* this exception may be swallowed by the pool.
*/
PassivateObject(ctx context.Context, object *PooledObject) error
}我们需要告诉连接池如何创建和销毁对象,才能使用它。
回到 cluster/client_pool.go 文件,定义一个 connectionFactory 结构体,实现 PooledObjectFactory 接口。这个结构体需要包含一个 peer 字段,用来存储节点的地址。
type connectionFactory struct {
Peer string // peer node id
}接下来,我们来实现 PooledObjectFactory 接口要求的方法。
首先是 MakeObject 方法。这个方法负责创建连接池中的对象。在这里,我们使用之前实现的 client.MakeClient 来创建一个新的客户端连接。创建成功后,调用 Start 方法启动客户端的后台 goroutine(处理读写和心跳),然后将这个客户端实例包装成 pool.PooledObject 返回。
// MakeObject creates a new connection object
func (f *connectionFactory) MakeObject(ctx context.Context) (*pool.PooledObject, error) {
c, err := client.MakeClient(f.Peer)
if err != nil {
return nil, err
}
c.Start()
return pool.NewPooledObject(c), nil
}然后是 DestroyObject 方法。当连接池决定要销毁一个对象时(比如连接失效或者池子缩容),会调用这个方法。我们需要从 PooledObject 中取出实际的客户端对象,然后调用它的 Close 方法来关闭连接和相关的 goroutine。
// DestroyObject destroys a connection object
func (f *connectionFactory) DestroyObject(ctx context.Context, pooledObject *pool.PooledObject) error {
c, ok := pooledObject.Object.(*client.Client)
if !ok {
return errors.New("invalid connection type")
}
c.Close()
return nil
}然后对于 ValidateObject 、ActivateObject 和 PassivateObject 方法,我们可以不实现,直接返回即可。
// ValidateObject validates a connection object
// We don't need it, just return true
func (f *connectionFactory) ValidateObject(ctx context.Context, pooledObject *pool.PooledObject) bool {
return true
}
// PassivateObject passivates a connection object
// We don't need it, just return nil
func (f *connectionFactory) PassivateObject(ctx context.Context, pooledObject *pool.PooledObject) error {
return nil
}
// ActivateObject activates a connection object
// We don't need it, just return nil
func (f *connectionFactory) ActivateObject(ctx context.Context, pooledObject *pool.PooledObject) error {
return nil
}这样,我们就完成了 connectionFactory 的实现。它告诉了连接池如何创建、销毁和验证我们的 client.Client 实例。有了这个工厂,我们就可以为集群中的每个对等节点(peer)创建一个连接池了。
我们在配置文件 redis.conf 中添加 self 和 peers 字段,分别表示当前节点的 ID 和集群中所有节点的 ID 列表。
self 127:0.0.1:6379
peers 127:0.0.1:6380,127:0.0.1:6381然后我们回到 cluster/cluster_database.go 文件,继续实现 ClusterDatabase 结构体。
我们需要实现 MakeClusterDatabase 函数来创建一个新的 ClusterDatabase 实例。
// MakeClusterDatabase creates a new ClusterDatabase instance
func MakeClusterDatabase() *ClusterDatabase {
cluster := &ClusterDatabase{
// 从配置中读取当前节点 ID
self: config.Properties.Self,
// 创建一个本地的 StandaloneDatabase 实例
db: databaseinstance.NewStandaloneDatabase(),
// 初始化一致性哈希环
peerPicker: consistenthash.NewNodeMap(nil),
// 初始化存储对等节点连接池的 map
peerConn: make(map[string]*pool.ObjectPool),
}
// 准备节点列表,包含所有 peer 和自身
nodes := make([]string, 0, len(config.Properties.Peers)+1)
// 添加所有 peer 节点
nodes = append(nodes, config.Properties.Peers...)
// 添加自身节点
nodes = append(nodes, config.Properties.Self)
// 将所有节点添加到一致性哈希环中
cluster.peerPicker.AddNodes(nodes...)
ctx := context.Background()
// 为每个 peer 节点创建连接池
for _, peer := range config.Properties.Peers {
// 使用之前定义的 connectionFactory 和默认配置创建对象池
cluster.peerConn[peer] = pool.NewObjectPoolWithDefaultConfig(ctx, &connectionFactory{
Peer: peer,
})
}
// 保存完整的节点列表
cluster.nodes = nodes
return cluster
}在这个函数里,我们做了几件事:
- 初始化
ClusterDatabase结构体:设置selfID,创建一个本地的StandaloneDatabase实例(用于存储当前节点负责的数据),初始化一致性哈希环 (peerPicker) 和连接池映射 (peerConn)。 - 构建节点列表:从配置
config.Properties中读取Peers(其他节点的地址列表)和Self(当前节点的地址),并将它们合并到一个nodes切片中。 - 填充一致性哈希环:调用
peerPicker.AddNodes(nodes...)将所有节点(包括自身)添加到一致性哈希环中。这样peerPicker就知道集群中有哪些节点以及它们在环上的位置。 - 创建连接池:遍历
config.Properties.Peers列表(注意,这里只为其他节点创建连接池,不需要和自己建立连接池)。对于每个peer,使用我们之前定义的connectionFactory和go-commons-pool的默认配置 (NewObjectPoolWithDefaultConfig) 来创建一个对象池。这个池子负责管理到该peer的client.Client连接。创建好的连接池存储在peerConn这个 map 中,以peer的地址作为键。 - 保存节点列表:将包含所有节点地址的
nodes切片保存在cluster.nodes字段中。 - 返回实例:返回初始化完成的
ClusterDatabase实例。
现在,ClusterDatabase 实例就绪了。它知道自己是谁 (self),集群里有哪些伙伴 (nodes 和 peerPicker),如何与这些伙伴建立连接 (peerConn),以及如何处理落在自己身上的数据 (db)。
Cluster 运作模式有几种,客户端发起请求后会随机选择一个节点进行处理。
- 第一种:不转发,只涉及自身的指令,如
PING直接调用本地数据库处理,然后返回客户端。 - 第二种:转发,涉及到其他节点的指令,如
SET、GET等。当某个节点收到请求的时候,会判断这个请求是否是针对自己的数据,如果是,就直接调用本地数据库处理;如果不是,就需要将请求转发到其他节点。别的节点处理完会返回结果给当前节点,当前节点再将结果返回给客户端。 - 第三种:群发,涉及到所有节点的指令,如
FLUSHDB、FLUSHALL等。这个时候需要将请求转发到所有节点,等待所有节点处理完后,再将结果返回给客户端。
接下来要为这三个模式建设基础设施。
在 cluster 包下创建 com.go 文件,负责处理集群通信。
首先是 getPeerClient 方法,它会根据给定的节点 ID 从连接池中获取一个连接对象。这个方法会检查连接池是否存在,如果不存在就返回错误。
// getPeerClient retrieves a client for the specified peer node
func (c *ClusterDatabase) getPeerClient(peer string) (*client.Client, error) {
pool, ok := c.peerConn[peer]
if !ok {
return nil, errors.New("peer not found")
}
conn, err := pool.BorrowObject(context.Background())
if err != nil {
return nil, err
}
client, ok := conn.(*client.Client)
if !ok {
return nil, errors.New("invalid connection type")
}
return client, nil
}这个方法会从连接池中借用一个连接对象,并返回给调用者。注意,这里我们使用了 pool.BorrowObject 方法来借用连接对象。
如果借用成功,我们需要将连接对象转换为 client.Client 类型,并返回给调用者。如果借用失败,或者转换失败,我们就返回错误。
有借有还,借完连接后要记得还回去。我们可以在 ClusterDatabase 结构体中实现一个 returnPeerClient 方法,用来归还连接对象。
// returnPeerClient returns a client to the specified peer node
func (c *ClusterDatabase) returnPeerClient(peer string, client *client.Client) {
pool, ok := c.peerConn[peer]
if !ok {
return
}
// Return the client to the pool
pool.ReturnObject(context.Background(), client)
}这个方法会将连接对象归还到连接池中。我们需要传入节点 ID 和连接对象,然后调用 pool.ReturnObject 方法将连接对象归还到连接池中。
然后我们可以使用这两个方法实现转发请求的逻辑。
还是在这个 com.go 文件中,定义一个 relayExec 方法,用来转发请求到其他节点。这是第一、第二种模式的处理逻辑。
// relay exec executes a command on the specified peer node
func (c *ClusterDatabase) relayExec(peer string, conn resp.Connection, args [][]byte) resp.Reply {
if peer == c.self {
return c.db.Exec(conn, args)
}
client, err := c.getPeerClient(peer)
if err != nil {
return reply.MakeStandardErrorReply(err.Error())
}
defer func() {
c.returnPeerClient(peer, client)
}()
client.Send(utils.ToCmdLine("SELECT", strconv.Itoa(conn.GetDBIndex())))
return client.Send(args)
}在转发真正的命令之前,先发送一个 SELECT 命令。这是非常关键的一步。因为 Redis 客户端可以选择不同的数据库。当一个命令需要转发时,我们必须确保它在目标节点上执行时,使用的数据库和原始客户端连接 (conn) 当前选择的数据库是同一个。conn.GetDBIndex() 获取原始客户端的 DB 索引,utils.ToCmdLine 将其组装成 SELECT <db_index> 命令,然后通过 client.Send 发送给目标节点。目标节点收到 SELECT 后会切换数据库,这样后续的命令就能在正确的上下文中执行了。
接下来,我们实现一个广播请求的方法 broadcastExec,用于处理第三种模式的请求。
// broadcastExec executes a command on all peer nodes
func (c *ClusterDatabase) broadcastExec(conn resp.Connection, args [][]byte) map[string]resp.Reply {
results := make(map[string]resp.Reply)
for _, peer := range c.nodes {
result := c.relayExec(peer, conn, args)
results[peer] = result
}
return results
}这个方法会遍历所有节点,调用 relayExec 方法将请求转发到每个节点。返回的结果会存储在一个 map 中,以节点 ID 为键,响应结果为值。
这样我们就完成了三种模式的基础设施。
我们怎么去判断如何使用这三种模式呢?
我们在 cluster/cluster_database.go 文件中创建一个 CmdFunc 类型,用来表示命令的处理函数。
type CmdFunc func(cluster *ClusterDatabase, conn resp.Connection, args [][]byte) resp.Reply我们在 cluster 下创建 router.go 文件,首先我们定义一个 defaultFunc 函数,它是一个默认的路由函数,默认情况下,我们会计算 GET key SET key 等命令的 key,然后通过一致性哈希算法选择一个节点进行转发。
// defaultFunc is a default function that executes a command on the cluster database
func defaultFunc(cluster *ClusterDatabase, conn resp.Connection, args [][]byte) resp.Reply {
key := string(args[1])
peer := cluster.peerPicker.PickNode(key)
return cluster.relayExec(peer, conn, args)
}然后我们创建一个 makeRouter 函数,用来创建一个路由器。这个路由器会根据命令的类型选择不同的处理函数。我们先把默认的路由函数放在这里,后续我们会添加更多的路由函数。
func makeRouter() map[string]CmdFunc {
routerMap := make(map[string]CmdFunc)
routerMap["exists"] = defaultFunc // exists key
routerMap["type"] = defaultFunc // type key
routerMap["set"] = defaultFunc // set key
routerMap["get"] = defaultFunc // get key
routerMap["setnx"] = defaultFunc // setnx key
routerMap["getset"] = defaultFunc // getset key
return routerMap
}然后到 cluster/cluster_database.go 文件中使用 makeRouter 函数创建一个路由。
var routerMap = makeRouter()接下来来实现一些比较特殊的指令的处理逻辑。
比如 ping 指令,它是一个特殊的指令,不需要转发到其他节点。也不能转发(没有 Key 供我们计算),所以我们需要单独处理。我们可以在 router.go 文件中实现一个 pingFunc 函数,用来处理 PING 指令。
// pingFunc is a function that executes a command on the cluster database
func pingFunc(cluster *ClusterDatabase, conn resp.Connection, args [][]byte) resp.Reply {
return cluster.db.Exec(conn, args)
}对于 rename 指令,我们需要先判断 key1 和 key2 是否在同一个节点上,如果在同一个节点上,就直接执行;如果不在同一个节点上,直接返回错误。
为啥?
我们来说说,在 Redis 集群里,如果你想把一个键 key1 改名成 key2,但这两个键在不同的节点上,会发生什么。
你得先搞清楚 key1 在哪个节点上(我们叫它源节点),key2 应该在哪个节点上(叫它目标节点)。这个位置是 Redis 根据哈希算法算出来的。
你需要去源节点把 key1 的值取出来。可以用 GET 命令,或者如果你担心数据类型不一样,也可以用 DUMP 命令来打包整个数据。如果 key1 根本就不存在,那就没法继续了,直接失败。
接下来,你拿着 key1 的值,去目标节点创建 key2。你可以用 SET 命令,或者用 RESTORE 来还原更复杂的数据类型。如果 key2 已经存在,也可以用 REPLACE 参数来覆盖它。
最后一步是回到源节点,把原来的 key1 删掉,用 DEL 命令搞定。
只有这三个步骤——取值、设置新键、删除旧键——都成功了,整个“改名字”的操作才算成功。
但是问题来了:这个过程不是原子的
也就是说,它不是一步到位的,中间任何一步出错,都会让数据变得不一致:
- 比如你刚刚取到值,但还没成功设置
key2,这时候如果崩了,就会有个值没地方放。 - 或者你成功设置了
key2,结果删除key1失败了,那就变成了两个一样的值同时存在,也不对。
正因为这个操作这么不靠谱,所以 Redis 官方的集群版 直接禁止这种跨节点的 RENAME 操作。只要两个键不在同一个哈希槽里,它就会报一个叫 "CROSSSLOT" 的错误,根本不让你执行。
总的来说,我们是可以用“先取值,再设置,再删除”的方式来实现这个功能的,但你得明白,这种方式不是安全的,和单节点上的 RENAME 命令比,它不能保证一步到位、不出错。
所以这里我们也不实现这个功能,直接返回错误。
// renameFunc is a function that executes a command on the cluster database
func renameFunc(cluster *ClusterDatabase, conn resp.Connection, args [][]byte) resp.Reply {
if len(args) != 3 {
return reply.MakeStandardErrorReply("ERR wrong number of arguments for 'rename' command")
}
src := string(args[1])
dest := string(args[2])
srcPeer := cluster.peerPicker.PickNode(src)
destPeer := cluster.peerPicker.PickNode(dest)
if srcPeer != destPeer {
return reply.MakeStandardErrorReply("ERR source and destination keys are on different nodes")
}
return cluster.relayExec(srcPeer, conn, args)
}然后我们来实现 flushdb 指令的处理逻辑。调用之前实现的 broadcastExec 方法,将请求转发到所有节点。这个指令会清空当前数据库的所有数据,所以我们需要在所有节点上执行。
// flushDBFunc is a function that executes a command on the cluster database
func flushDBFunc(cluster *ClusterDatabase, conn resp.Connection, args [][]byte) resp.Reply {
replies := cluster.broadcastExec(conn, args)
var errReply reply.ErrorReply
for _, r := range replies {
if reply.IsErrReply(r) {
errReply = r.(reply.ErrorReply)
break
}
}
if errReply == nil {
return reply.MakeOKReply()
}
return reply.MakeStandardErrorReply("error: " + errReply.Error())
}得到一个 replies 列表,包含所有节点的响应结果。我们遍历这个列表,检查是否有错误发生。如果有错误,就返回错误信息;如果没有错误,就返回成功的响应。
然后是 del 指令的处理逻辑。由于传入的参数是一个或多个键,他们可能分布在不同的节点上,所以我们需要遍历所有节点,调用 broadcastExec 方法将请求转发到每个节点。返回的结果会存储在一个 map 中,以节点 ID 为键,响应结果为值。
// delFunc is a function that executes a command on the cluster database
// delFunc is a function that executes a command on the cluster database
func delFunc(cluster *ClusterDatabase, c resp.Connection, args [][]byte) resp.Reply {
// Check the number of arguments
if len(args) < 2 {
return reply.MakeArgNumErrReply("del")
}
// If there is only one key, route directly to the corresponding node
if len(args) == 2 {
key := string(args[1])
peer := cluster.peerPicker.PickNode(key)
// Note: The full command, including "DEL", needs to be passed
fullArgs := make([][]byte, 2)
fullArgs[0] = []byte("DEL")
fullArgs[1] = args[1]
return cluster.relayExec(peer, c, fullArgs)
}
// --- Modification starts ---
// Handle multiple keys: group keys by node
groupedKeys := make(map[string][][]byte) // key: peer address, value: list of keys handled by the peer
for i := 1; i < len(args); i++ { // Iterate over all keys to delete, starting from index 1
key := string(args[i])
peer := cluster.peerPicker.PickNode(key)
if _, ok := groupedKeys[peer]; !ok {
groupedKeys[peer] = make([][]byte, 0)
}
groupedKeys[peer] = append(groupedKeys[peer], args[i]) // Add the original []byte key to the list
}
// Execute delete operation for each node
var deleted int64 = 0
var firstErrReply reply.ErrorReply // Save the first encountered error
for peer, keys := range groupedKeys {
// Construct the DEL command for the current node: ["DEL", key1, key2, ...]
nodeArgs := make([][]byte, len(keys)+1)
nodeArgs[0] = []byte("DEL") // The command itself
copy(nodeArgs[1:], keys) // Copy the list of keys handled by this node
// Send the command to the specific node
nodeReply := cluster.relayExec(peer, c, nodeArgs)
// Handle the response
if reply.IsErrReply(nodeReply) {
// If it is an error response, record the first error and stop processing other nodes (optional, can also choose to continue processing other nodes)
if firstErrReply == nil {
if errReply, ok := nodeReply.(reply.ErrorReply); ok {
firstErrReply = errReply
} else {
firstErrReply = reply.MakeStandardErrorReply("unknown error from peer")
}
}
// You can choose to break or continue here, depending on whether you want the entire operation to fail if one node fails
// break // Stop and return an error if one node fails
continue // Continue attempting to delete keys on other nodes, then summarize results or return the first error
}
// If it is an integer response, accumulate the number of deleted keys
if intReply, ok := nodeReply.(*reply.IntReply); ok {
deleted += intReply.Code
} else {
// If the response is neither the expected integer nor an error, treat it as an error
if firstErrReply == nil {
firstErrReply = reply.MakeStandardErrorReply("unexpected reply type from peer")
}
// break // Same as above
continue // Same as above
}
}
// If an error was encountered during processing, return the first error
if firstErrReply != nil {
// You can choose to return more detailed error information or just the first error
return reply.MakeStandardErrorReply("error occurs during multi-key delete: " + firstErrReply.Error())
}
// If all nodes succeeded (or partial errors were ignored), return the total number of deleted keys
return reply.MakeIntReply(deleted)
}这个方法会遍历所有的键,计算出每个键所在的节点,然后将这些键分组到对应的节点上。最后,我们对每个节点执行 DEL 命令,删除对应的键。
这里不能直接使用广播,因为 DEL 命令是针对特定的键的,而不是针对整个数据库的。我们需要根据键的哈希值来确定它所在的节点,然后将删除请求转发到对应的节点。否则将会导致多个节点之间循环广播的问题。
然后是 select 指令的处理逻辑。它和 PING 指令类似,不需要转发到其他节点。我们可以直接调用本地数据库的 Exec 方法来处理这个指令。
// selectFunc is a function that executes a command on the cluster database
func selectFunc(cluster *ClusterDatabase, conn resp.Connection, args [][]byte) resp.Reply {
return cluster.db.Exec(conn, args)
}然后将上面实现的这些函数添加到路由器中:
func makeRouter() map[string]CmdFunc {
routerMap := make(map[string]CmdFunc)
routerMap["exists"] = defaultFunc // exists key
routerMap["type"] = defaultFunc // type key
routerMap["set"] = defaultFunc // set key
routerMap["get"] = defaultFunc // get key
routerMap["setnx"] = defaultFunc // setnx key
routerMap["getset"] = defaultFunc // getset key
routerMap["ping"] = pingFunc // ping command
routerMap["rename"] = renameFunc // rename key
routerMap["renamex"] = renameFunc
routerMap["flushdb"] = flushDBFunc // flushdb command
routerMap["del"] = delFunc // del key
routerMap["select"] = selectFunc // select database
return routerMap
}下面我们就要开始实现 Exec 方法了。回到 cluster/cluster_database.go 文件,来实现 Close 和 AfterClientClose 方法。
// Close closes the cluster database
func (c *ClusterDatabase) Close() {
c.db.Close()
}
// AfterClientClose is called after a client closes
func (c *ClusterDatabase) AfterClientClose(client resp.Connection) {
c.db.AfterClientClose(client)
}直接调用 db 的 Close 和 AfterClientClose 方法。
然后我们来实现 Exec 方法。这个方法会根据命令的类型选择不同的处理函数。
// Exec executes a command on the cluster database
func (c *ClusterDatabase) Exec(client resp.Connection, args [][]byte) (result resp.Reply) {
defer func() {
if err := recover(); err != nil {
logger.Error("ClusterDatabase Exec panic:" + err.(error).Error())
result = reply.MakeUnknownReply()
}
}()
cmdName := strings.ToLower(string(args[0]))
if cmdFunc, ok := routerMap[cmdName]; ok {
return cmdFunc(c, client, args)
} else {
result = reply.MakeStandardErrorReply("ERR unknown command '" + cmdName + "'")
}
return
}在这个方法里,我们首先获取命令的名称,然后根据命令名称从路由器中获取对应的处理函数。如果找到了,就调用这个函数来处理命令;如果没有找到,就返回一个错误的响应。
但是目前这个 MakeClusterDatabase 方法是没有被调用的。
我们来到 resp/handle/handle.go 文件,修改 MakeHandle 方法,来创建一个 ClusterDatabase 实例。
// MakeHandler creates a RespHandler instance
func MakeHandler() *RespHandler {
var db databaseface.Database
// If self is not empty, it means this is a cluster node
// and we need to create a cluster database
if config.Properties.Self != "" && len(config.Properties.Peers) > 0 {
db = cluster.MakeClusterDatabase()
} else {
db = database.NewStandaloneDatabase()
}
return &RespHandler{
db: db,
}
}这里我们判断 config.Properties.Self 是否为空,如果不为空,就创建一个 ClusterDatabase 实例;否则就创建一个 StandaloneDatabase 实例。
测试
现在我们设置 redis.conf 文件,配置 self port 和 peers 字段。
bind 0.0.0.0
port 6379
databases 16
appendonly yes
appendfilename appendonly.aof
self 127.0.0.1:6379
peers 127.0.0.1:6380由于现在我们需要开启多个实例进行测试,所以我们运行 go build 编译成二进制文件。
执行完毕后我们可以在根目录下看到一个 redis 的二进制文件。 Windows下会生成 redis.exe 文件。
在别的地方新建一个文件夹,并将这个 redis 二进制文件复制到这个文件夹下。还有 redis.conf 配置文件。
然后修改项目中的 redis.conf 文件,设置 self 和 peers 字段。
bind 0.0.0.0
port 6380
databases 16
appendonly yes
appendfilename appendonly.aof
self 127.0.0.1:6380
peers 127.0.0.1:6379执行 go run main.go 启动 Redis 实例(127.0.0.1:6380)
然后在刚刚的文件夹双击 redis 二进制文件,启动 Redis 实例(127.0.0.1:6379)
然后我们新建两个终端,使用 redis-cli 连接到这两个实例。
redis-cli -h 127.0.0.1 -p 6379
redis-cli -h 127.0.0.1 -p 6380然后我们在 6379 实例中执行 PING 命令,看看是否能正常响应。
PING运行正常回复 PONG。
然后我们在 6380 实例中执行 PING 命令,看看是否能正常响应。
PING运行正常回复 PONG。
然后我们在 6379 实例中执行 SET 命令,看看是否能正常响应。
SET key1 value1我们看到回复了 OK。
然后我们到 6380 实例中执行 GET 命令,看看是否能正常响应。
GET key1这里我在 MacOS 上遇到一个问题,就是当我打包了二进制文件到别的文件夹后,运行时找不到配置文件。
所以我修改了 main.go 文件,帮助二进制文件找到自己的工作目录下的配置文件。如果遇到同样的问题,可以前往 main.go 查看。
完成修改后,我们重新编译二进制文件,启动两个实例。
在 6379 实例中执行 SET 命令,看看是否能正常响应。
SET key1 value1我们看到回复了 OK。
然后我们到 6380 实例中执行 GET 命令,看看是否能正常响应。
GET key1我们看到回复了 value1。
然后我们在 6380 实例中执行 SET 命令,看看是否能正常响应。
SET key2 value2我们看到回复了 OK。
然后我们到 6379 实例中执行 GET 命令,看看是否能正常响应。
GET key2我们看到回复了 value2。
然后我们在 6379 实例中执行 DEL 命令,看看是否能正常响应。
DEL key1我们看到回复了 1。
这就表示我们的集群模式已经搭建完成了。
总结
在这一章中,我们实现了 Redis 集群的基本功能。我们使用了一致性哈希算法来选择节点,并使用连接池来管理与其他节点的连接。我们还实现了转发请求和广播请求的逻辑。
我们实现了 PING、SET、GET、DEL、FLUSHDB 等命令的处理逻辑,并且处理了一些特殊的命令,如 RENAME 和 SELECT。
我们还实现了一个简单的路由器,根据命令的类型选择不同的处理函数。
最后,我们测试了集群的基本功能,验证了集群模式的正确性。